|
Ron Mokady
I’m the VP of Research at BRIA AI, leading the research and training of visual generative AI models using licensed data.
Previously, I was a Computer Science Ph.D. student at Tel-Aviv University, under the supervision of Prof. Daniel Cohen-Or and Dr. Amit H. Bermano.
During that time, I spent the 2020 summer at FAIR under the supervision of Prof. Lior Wolf, and the 2021 and 2022 summers at Google.
My main research interest is machine learning applications for computer vision and graphics.
In particular, I work on image and video synthesis, while also interested in disentanglement, temporal coherence, supervision reduction, and the utilization of pre-trained models.
Email /
Github /
LinkedIn /
Google Scholar /
Semantic Scholar /
Twitter
|

|
|
|
SemanticMoments: Training-Free Motion Similarity via Third Moment Features
Saar Huberman,
Kfir Goldberg,
Or Patashnik,
Sagie Benaim,
Ron Mokady
CVPR (Findings), 2026.
arXiv
|
|
|
Image Generation from Contextually-Contradictory Prompts
Saar Huberman,
Or Patashnik,
Omer Dahary,
Ron Mokady,
Daniel Cohen-Or
CVPR, 2026.
project page /
arXiv
|
|
|
Token-to-Token Alignment of Text Embeddings for Semantic Blending
Saar Huberman,
Ron Mokady,
Or Patashnik,
Daniel Cohen-Or
arXiv, 2026.
arXiv
|
|
|
BBQ-to-Image: Numeric Bounding Box and Qolor Control in Large-Scale Text-to-Image Models
Eliran Kachlon,
Alexander Visheratin,
Nimrod Sarid,
Tal Hacham,
Eyal Gutflaish,
Saar Huberman,
Hezi Zisman,
David Ruppin,
Ron Mokady
arXiv, 2026.
arXiv
|
|
|
Generating an Image From 1,000 Words: Enhancing Text-to-Image With Structured Captions
Eyal Gutflaish,
Eliran Kachlon,
Hezi Zisman,
Tal Hacham,
Nimrod Sarid,
Alexander Visheratin,
Saar Huberman,
Gal Davidi,
Guy Bukchin,
Kfir Goldberg,
Ron Mokady
arXiv, 2025.
arXiv /
model (FIBO)
|
|
|
Blended Point Cloud Diffusion for Localized Text-guided Shape Editing
Etai Sella,
Noam Atia,
Ron Mokady,
Hadar Averbuch-Elor
ICCV, 2025.
project page /
arXiv
|
|
|
NULL-text Inversion for Editing Real Images using Guided Diffusion Models
Ron Mokady*,
Amir Hertz*,
Kfir Aberman,
Yael Pritch,
Daniel Cohen-Or,
(* denotes equal contribution)
CVPR, 2023.
project page /
code /
arXiv
|
|
|
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz,
Ron Mokady,
Jay Tenenbaum,
Kfir Aberman,
Yael Pritch,
Daniel Cohen-Or
ICLR, 2023.
project page /
code /
paper
arXiv
|
|
|
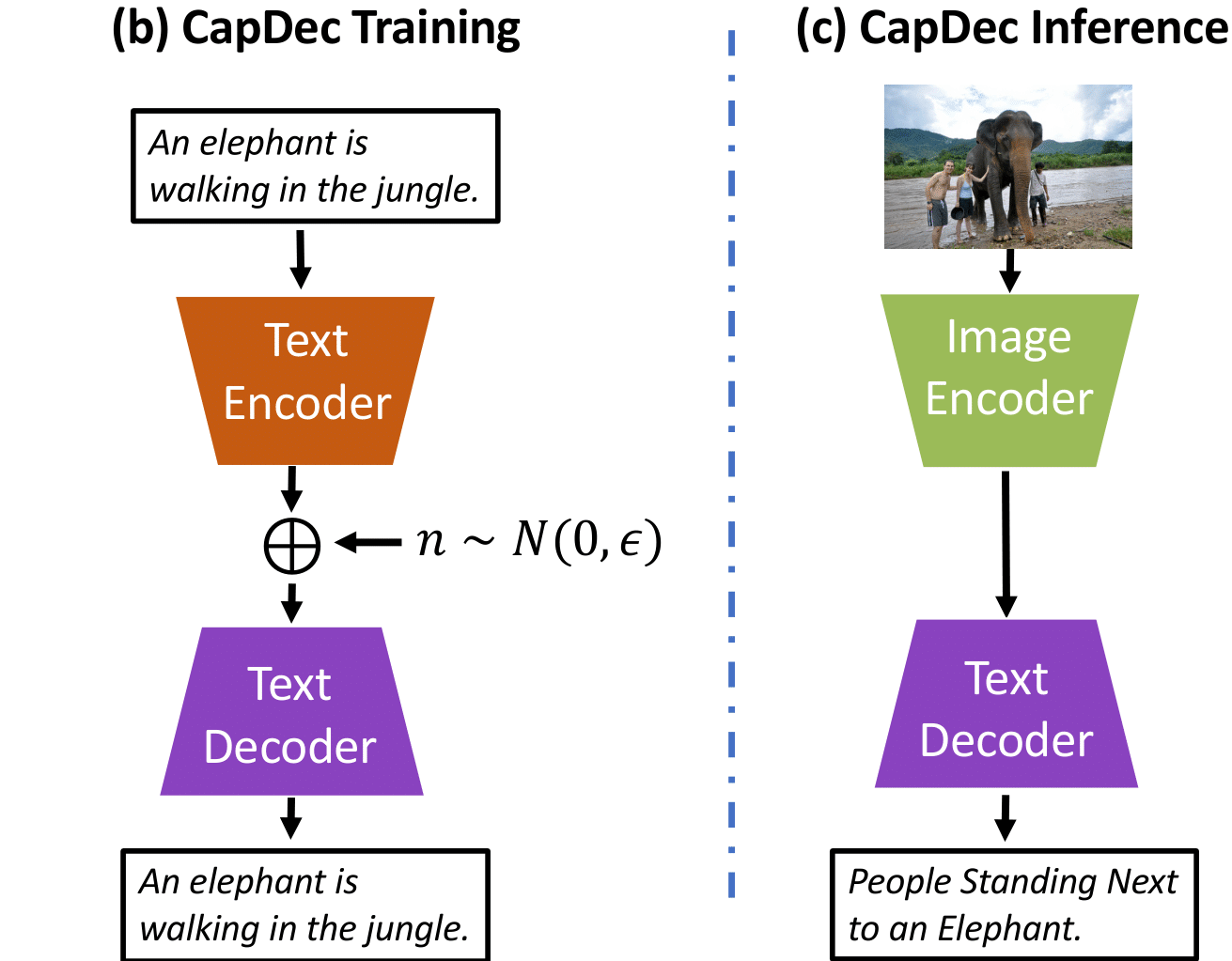
Text-Only Training for Image Captioning using Noise-Injected CLIP
David Nukrai,
Ron Mokady,
Amir Globerson
Findings of EMNLP, 2022.
arXiv
|
|
|
Self-Distilled StyleGAN: Towards Generation from Internet Photos
Ron Mokady,
Michal Yarom,
Omer Tov,
Oran Lang,
Daniel Cohen-Or,
Tali Dekel,
Michal Irani,
Inbar Mosseri
SIGGRAPH, 2022.
project page /
arXiv /
Supplementary /
Datasets and Models
|
|
|
Stitch it in Time: GAN-Based Facial Editing of Real Videos
Rotem Tzaban,
Ron Mokady,
Rinon Gal,
Amit H. Bermano,
Daniel Cohen-Or
SIGGRAPH ASIA, 2022.
project page /
arXiv /
code
|
|
|
State-of-the-Art in the Architecture, Methods and Applications of StyleGAN
Amit H. Bermano,
Rinon Gal,
Yuval Alaluf,
Ron Mokady,
Yotam Nitzan,
Omer Tov,
Or Patashnik,
Daniel Cohen-Or
EUROGRAPHICS (STAR), 2022.
arXiv
|
|
|
ClipCap: CLIP Prefix for Image Captioning
Ron Mokady,
Amir Hertz,
Amit H. Bermano,
arXiv, 2021.
arXiv /
code
|
|
|
HyperStyle: StyleGAN Inversion with HyperNetworks for Real Image Editing
Yuval Alaluf*,
Omer Tov*,
Ron Mokady,
Rinon Gal,
Amit H. Bermano,
CVPR, 2022.
project page /
arXiv /
code
|
|
|
Pivotal Tuning for Latent-based Editing of Real Images
Daniel Roich,
Ron Mokady,
Amit H. Bermano,
Daniel Cohen-Or
Transactions On Graphics, 2022.
arXiv /
TOG /
code
|
|
|
JOKR: Joint Keypoint Representation for Unsupervised Cross-Domain Motion Retargeting
Ron Mokady,
Rotem Tzaban,
Sagie Benaim,
Amit H. Bermano,
Daniel Cohen-Or
Computer Graphics Forum, 2022.
project page /
arXiv /
code
|
|
|
Structural-analogy from a Single Image Pair
Sagie Benaim*,
Ron Mokday*,
Amit H. Bermano,
Daniel Cohen-Or,
Lior Wolf
(* denotes equal contribution)
Computer Graphics Forum, 2020.
Also in the Deep Internal Learning workshop, ECCV 2020.
project page /
arXiv /
code /
video
|
|
|
Masked Based Unsupervised Content Transfer
Ron Mokday,
Sagie Benaim,
Amit H. Bermano,
Lior Wolf
ICLR, 2020.
paper /
code /
video
|
Exploring the Intermediate Language of Visual GenAI. Generative Media TLV, 2026.
Video
Tired of the AI Lottery? Bria's FIBO Model Gives Creators the Control. GMI Cloud Podcast, 2026.
Video
Beyond the Arena: Building Image Generation Models for Professional Use. fal, 2025.
Video
Prompt-To-Prompt Editing with Diffusion Models. Israeli Computer Vision Day 2023.
Video
Moving forward with StyleGAN to Real Data and New Domains. TAU Visual Computing Seminar, Technion Pixel Club, Weizmann Institute seminar, 2022.
PDF
Deep Video Synthesis. PKU VCL Seminar, 2020.
PDF
Mask Based Unsupervised Content Transfer. Alibaba's Deep academy, 2020.
Video (Hebrew)
Image Generation Using Disentanglement. Tel-Aviv University Visual Computing Seminar, 2019.
PDF
|
Workshop in Machine Learning Applications for Computer Graphics (2019/20) @ TAU
Workshop On Image Processing Based On Deep Networks (2020/21) @ TAU
|
This page design is based on a template by Jon Barron.
|